

Le laboratoire de recherche DeepMind AI a créé la carte la plus complète des protéines humaines à ce jour à l’aide de l’IA. La société, une filiale de la filiale Alphabet de Google, publie les données gratuitement, certains scientifiques comparant l’impact potentiel du travail avec celui du Human Genome Project, un effort international pour cartographier chaque gène humain.
Les protéines sont de longues molécules complexes qui effectuent de nombreuses tâches dans le corps, de la construction des tissus à la lutte contre les maladies. Son objectif était déterminé par sa structure, qui se plie comme un origami en des formes complexes et irrégulières. Comprendre comment une protéine se replie aide à expliquer sa fonction, ce qui à son tour aide les scientifiques dans diverses tâches, de la recherche fondamentale sur le fonctionnement du corps à la conception de nouveaux médicaments et traitements.
Auparavant, la détermination de la structure des protéines reposait sur des expériences coûteuses et chronophages. Mais DeepMind a montré l’année dernière qu’il peut produire Prédictions précises de la structure des protéinesهيكل Utilisation d’un programme d’IA appelé AlphaFold. Maintenant, la société publie des centaines de milliers de prédictions que le programme a faites au public.
« Je vois cela comme l’aboutissement de dix années complètes de la vie de DeepMind », a déclaré Demis Hassabis, PDG et co-fondateur de la société. le bord. « Depuis le début, c’est ce que nous nous sommes fixé pour objectif : faire des percées dans l’IA, tester cela dans des jeux comme Go et Atari, [and] Appliquez cela aux problèmes du monde réel, pour voir si nous pouvons accélérer les percées scientifiques et les utiliser au profit de l’humanité. »
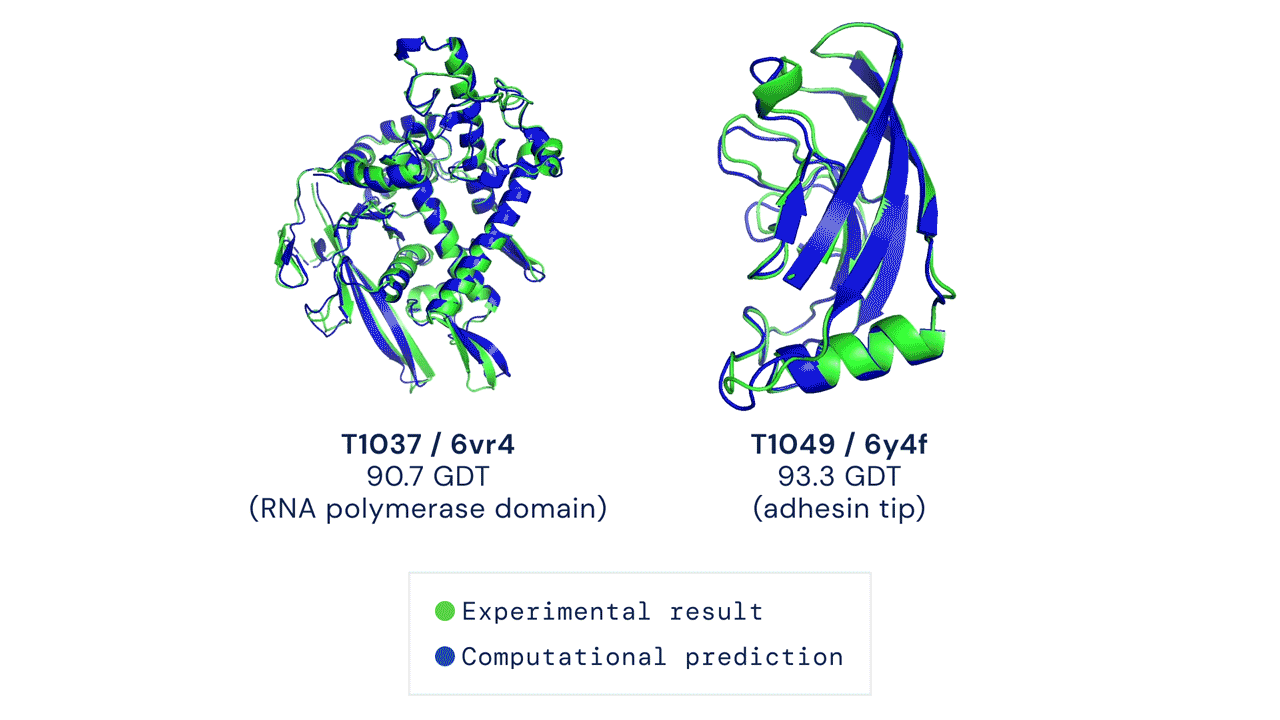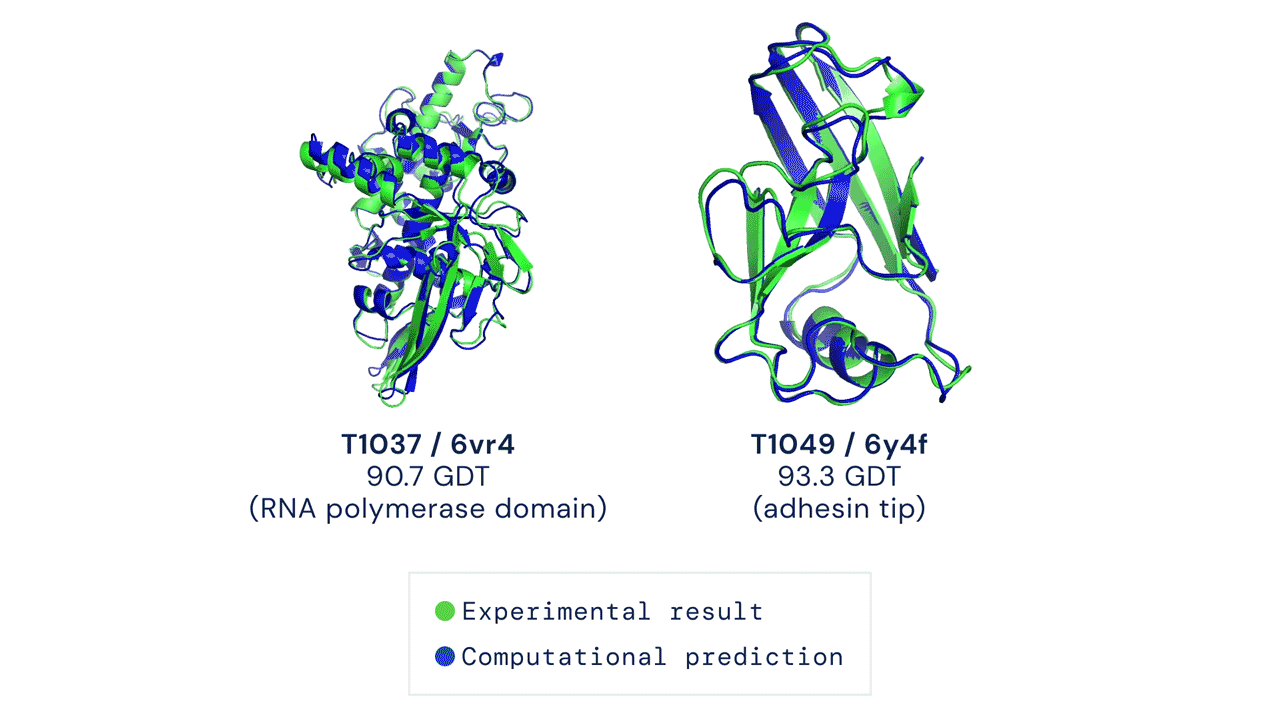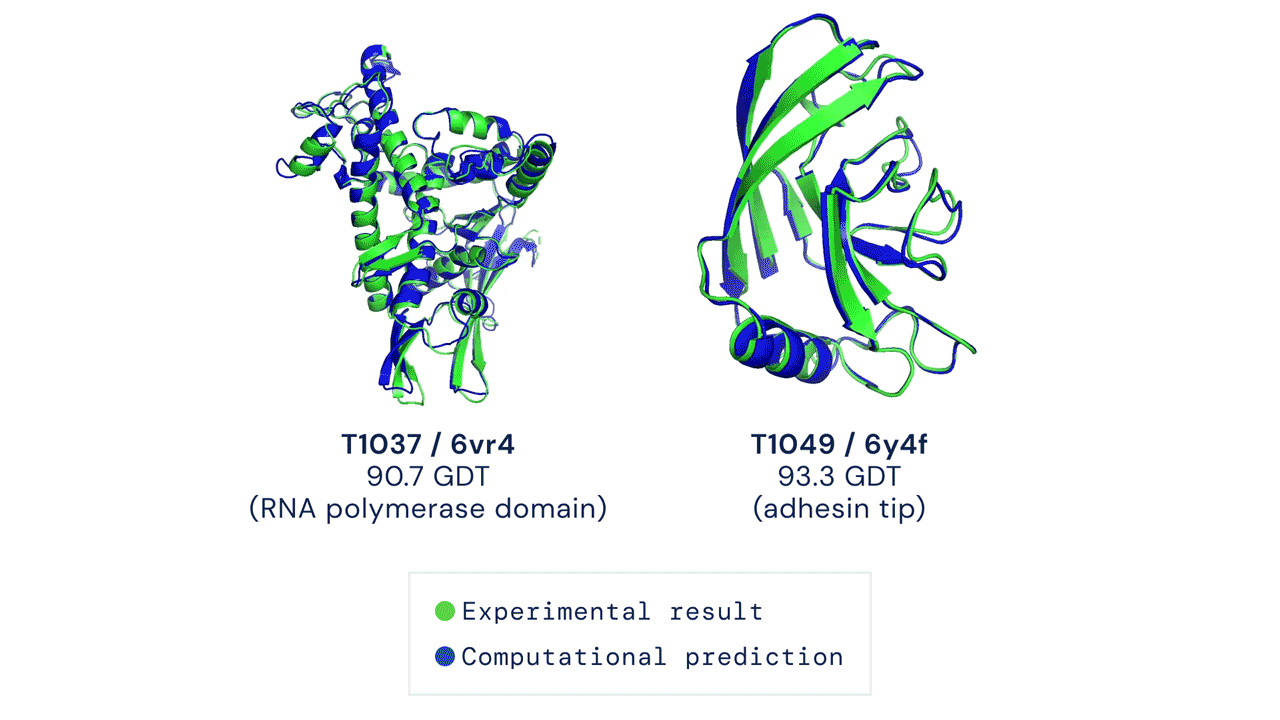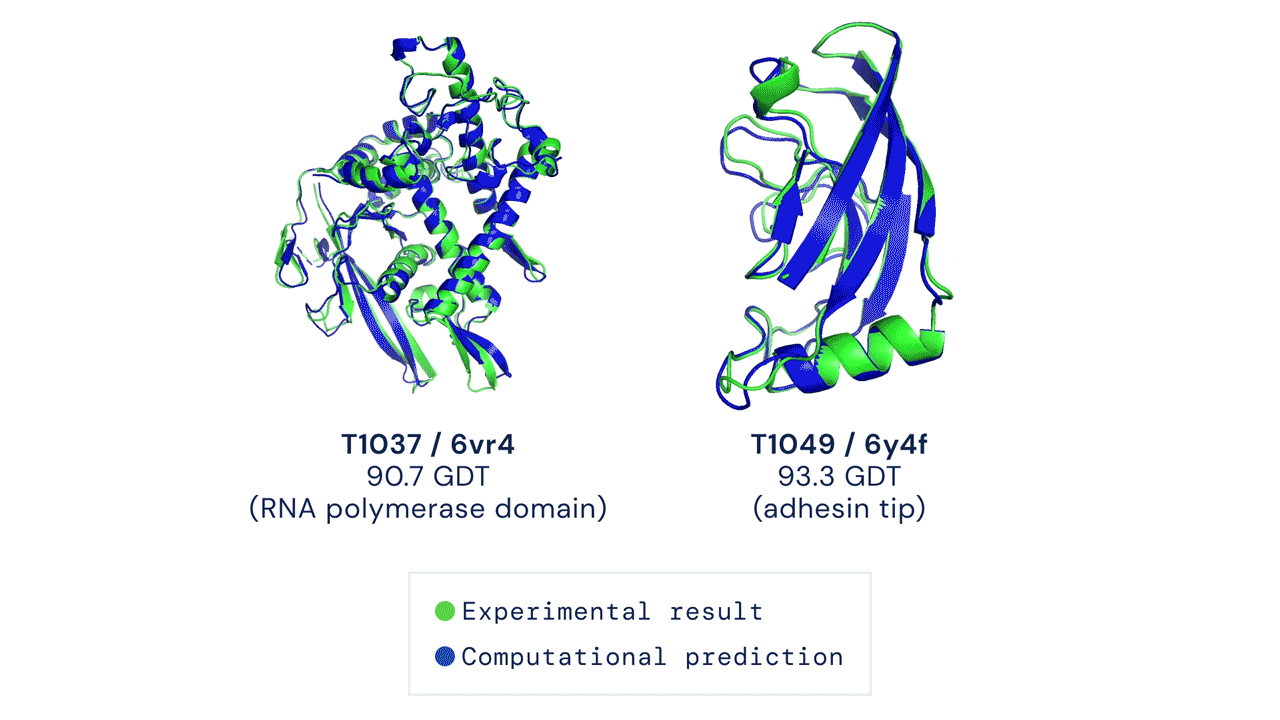
Il existe actuellement environ 180 000 structures protéiques disponibles dans le domaine public, chacune étant produite par des méthodes expérimentales et accessible via la banque de données sur les protéines. DeepMind fait des prédictions sur la structure d’environ 350 000 protéines dans 20 organismes différents, y compris des animaux tels que les souris et les mouches des fruits, et des bactéries telles que bactéries coli. (Il y a un certain chevauchement entre les données DeepMind et les structures protéiques préexistantes, mais exactement ce qui est difficile à déterminer en raison de la nature des modèles.) Il est important de noter que la publication comprend des prédictions pour 98% de toutes les protéines humaines, environ 20 000 structures différentes , qui sont collectivement connus sous le nom de protéome humain. pas lui Le premier ensemble de données publiques pour les protéines humainesMais c’est le plus complet et le plus précis.
S’ils le souhaitent, les scientifiques peuvent télécharger l’intégralité de la protéine humaine pour eux-mêmes, explique John Jumper, responsable technique d’AlphaFold. « Le fichier HumanProteome.zip est effectivement là, je pense qu’il fait environ 50 Go », explique Jumper. le bord. « Vous pouvez le mettre sur une clé USB si vous le souhaitez, même si cela ne vous fera pas grand-chose sans un ordinateur pour l’analyser ! »
Après avoir publié ce premier ensemble de données, DeepMind prévoit de continuer à ajouter des protéines à son référentiel, qui sera détenu par le principal laboratoire européen des sciences de la vie, le Laboratoire européen de biologie moléculaire (EMBL). D’ici la fin de l’année, DeepMind espère publier des prédictions pour 100 millions de structures protéiques, un ensemble de données qui « transformera notre compréhension du fonctionnement de la vie », selon Edith Hurd, directrice générale de l’EMBL.
Hasbis affirme que les données seront gratuites pour toujours pour les chercheurs scientifiques et commerciaux. « Tout le monde peut l’utiliser pour n’importe quoi », a déclaré le PDG de DeepMind lors d’une conférence de presse. « Ils ont juste besoin de rendre hommage aux personnes impliquées dans la citation. »
Comprendre la structure des protéines est utile aux scientifiques dans de nombreux domaines. Les informations pourraient aider à concevoir de nouveaux médicaments, à synthétiser de nouvelles enzymes qui décomposent les déchets et à créer des cultures résistantes aux virus ou aux intempéries. Déjà, les prédictions de protéines DeepMind. sont utilisées recherche médicale, y compris l’étude Comment fonctionne le SRAS-CoV-2, le virus qui cause le COVID-19.
De nouvelles données accéléreront ces efforts, mais les scientifiques notent que transformer ces informations en résultats réalistes prendra du temps. « Je ne pense pas que ce sera quelque chose qui changera la façon dont les patients sont traités au cours de l’année, mais cela aura certainement un impact significatif sur la communauté scientifique », a déclaré Marcelo C. Souza, professeur au département de l’Université du Colorado. de Biochimie. le bord.
Catherine Tuniasovunakul, chercheuse principale chez DeepMind, affirme que les scientifiques devront s’habituer à avoir de telles informations à portée de main. « En tant que biologiste, je peux confirmer que nous n’avons pas de preuves de base pour même examiner 20 000 structures, c’est donc [amount of data] tuniasofunakol a dit le bord. « Analyser des centaines de milliers de structures, c’est fou. »
En particulier, cependant, DeepMind . Prévisions à partir de structures protéiques plutôt que de modèles déterminés expérimentalement, ce qui signifie que, dans certains cas, des travaux supplémentaires seront nécessaires pour vérifier la structure. DeepMind dit avoir passé beaucoup de temps à créer des mesures de précision dans son logiciel AlphaFold, qui classe le degré de confiance de chaque prédiction.
:format(webp):no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/22732723/Proteins.jpg)
Cependant, les prédictions des structures des protéines sont toujours très utiles. Déterminer la structure d’une protéine par des méthodes expérimentales est coûteux, prend du temps et repose sur de nombreux essais et erreurs. Cela signifie que même une prédiction peu fiable peut économiser des années de travail aux scientifiques en les guidant dans la bonne direction pour la recherche.
Helen Walden, professeur de biologie structurale à l’Université de Glasgow le bord Que les données de DeepMind « soulageront considérablement » les goulots d’étranglement de la recherche, mais que « le travail acharné qui draine les ressources pour mener des évaluations biochimiques et biologiques, par exemple, des fonctions des médicaments » restera.
Souza, qui a déjà utilisé les données d’AlphaFold dans son travail, dit que les scientifiques ressentiront l’effet tout de suite. « Dans notre collaboration avec DeepMind, nous avions un ensemble de données avec un échantillon de protéines que nous avions depuis 10 ans, et nous n’avons jamais réussi à développer un modèle approprié », dit-il. « DeepMind a accepté de nous fournir un châssis, et ils ont pu résoudre le problème en 15 minutes après que nous nous soyons assis dessus pendant 10 ans. »
Pourquoi le repliement des protéines est-il si difficile
Les protéines sont constituées de chaînes d’acides aminés, qui sont de 20 types différents dans le corps humain. Étant donné que toute protéine individuelle peut être constituée de centaines d’acides aminés individuels, chacun pouvant se plier et se tordre dans des directions différentes, cela signifie que la structure finale de la molécule a un nombre incroyablement grand de configurations possibles. Une Appréciation est qu’une protéine typique peut être pliée de 10 à 300 façons – c’est-à-dire 1 suivie de 300 zéros.
Parce que les protéines sont trop petites pour être examinées au microscope, les scientifiques ont dû déterminer indirectement leur structure en utilisant des méthodes coûteuses et complexes telles que la résonance magnétique nucléaire et la cristallographie aux rayons X. L’idée de déterminer la structure d’une protéine simplement en lisant la liste de ses acides aminés constitutifs a longtemps été théorique mais difficile à réaliser, conduisant beaucoup à la décrire comme un « grand défi » pour la biologie.
Mais ces dernières années, les méthodes de calcul – en particulier celles utilisant l’intelligence artificielle – ont suggéré qu’une telle analyse est possible. À l’aide de ces techniques, les systèmes d’IA sont entraînés sur des ensembles de données de structures protéiques connues et utilisent ces informations pour créer leurs propres prédictions.
:format(webp):no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/22732721/Median_Free_Modelling_Accuracy.png)
De nombreux groupes travaillent sur ce problème depuis des années, mais la plate-forme approfondie de DeepMind pour les talents d’IA et l’accès aux ressources informatiques lui a permis d’accélérer considérablement les progrès. L’année dernière, la société a participé à une compétition internationale de repliement des protéines connue sous le nom de CASP et a fait exploser la compétition. ses résultats C’était très précis Le biologiste informatique John Molt, l’un des fondateurs de CASP, a déclaré que « dans un sens, le problème [of protein folding] résolu. »
AlphaFold de DeepMind a été mis à niveau depuis le concours CASP de l’année dernière et est maintenant 16 fois plus rapide. « Nous pouvons plier la protéine moyenne en quelques minutes, et dans la plupart des cas en quelques secondes », explique Hasbis. La compagnie a également Libérer le code de base Il a publié AlphaFold la semaine dernière en open source, permettant à d’autres de s’appuyer sur son travail à l’avenir.
Liam McGuffin, professeur à l’Université de Reading qui a développé certains des principaux programmes de repliement des protéines du Royaume-Uni, a salué l’intelligence technique d’AlphaFold, mais a également noté que le succès du programme reposait sur des décennies de recherches antérieures et de données publiques. « DeepMind dispose d’énormes ressources pour mettre à jour cette base de données, et ils sont mieux placés pour le faire que n’importe quel groupe universitaire », a déclaré McGuffin. le bord. « Je pense que les universitaires y seraient finalement arrivés, mais cela aurait pu être plus lent parce que nous n’avions pas assez de ressources. »
Pourquoi DeepMind s’en soucie-t-il ?
De nombreux savants le bord Parlez à la générosité de DeepMind en publiant ces données gratuitement. Après tout, le laboratoire appartient à la filiale de Google Alphabet, qui a investi des quantités massives de ressources dans des projets de soins de santé commerciaux. DeepMind lui-même perdre beaucoup d’argent Chaque année, il y a eu plusieurs Rapports des tensions entre l’entreprise et la société mère sur des questions telles que l’indépendance de la recherche et la viabilité commerciale.
Mais d’après les comptes le bord Que la société a toujours prévu de rendre ces informations disponibles gratuitement, et que cela est conforme à l’esprit fondateur de DeepMind. Il souligne que le travail de DeepMind est utilisé dans de nombreux endroits chez Google – « presque tout ce que vous utilisez, il y a une partie de notre technologie qui en fait partie sous le capot » – mais l’objectif principal de l’entreprise a toujours été la recherche fondamentale.
« L’accord lorsque nous l’avons obtenu est que nous sommes ici principalement pour développer des technologies d’IA et d’IA de pointe, puis les utiliser pour accélérer les réalisations scientifiques », a déclaré Hasbis. « [Alphabet] Il a beaucoup de départements concentrés sur l’argent », ajoute-t-il, notant que l’accent mis par DeepMind sur la recherche « apporte toutes sortes d’avantages, en termes de prestige et de bonne volonté pour la communauté scientifique. Il existe de nombreuses façons d’obtenir de la valeur.
Hassabis anticipe qu’AlphaFold est un signe des choses à venir – un projet qui montre l’énorme potentiel de l’intelligence artificielle pour s’attaquer à des problèmes aussi compliqués que la biologie humaine.
« Je pense que nous sommes dans un moment vraiment excitant », dit-il. « Au cours de la prochaine décennie, nous et d’autres acteurs du domaine de l’intelligence artificielle espérons réaliser des percées incroyables qui accéléreront vraiment les solutions aux très gros problèmes auxquels nous sommes confrontés ici sur Terre. »

")



